IBM Cloud Pak for Data System
A software and hardware management platform for system administrators to ensure that their IT infrastructure is running smoothly and efficiently and enables users to collect, organize, and analyze their data within a single, unified platform.

Timeline: January 2019 - May 2020
My role: Project lead, UX designer
As a project lead, I acted as the liaison for the design team in communicating our needs or concerns to the larger team and making sure that we are all aligned so that expectations from all sides are clear. While we all had our own pages and features that we were responsible for, we all helped one another throughout the process, whether that meant gathering requirements from stakeholders, giving feedback or suggestions on designs, or providing whatever support was needed to meet tight deadlines.

The design problem
With complex IT framework that combine software and hardware infrastructure, issues regarding configuration, performance degradation, storage unavailability, and hardware failures are inevitable. IT staff at these data centers must stay vigilant in identifying bottlenecks and quickly fixing any issues that arise so as to avoid unwanted outages and downtime for their company. However, the more hardware and components there are that make up the framework, the more complicated it can get to make sure everything is working and running smoothly.
How might we ensure that system administrators can effectively and efficiently maintain their hardware and software infrastructures?
Emmet, the system administrator
Other possible role titles: IT administrator, systems engineer, network administrator
A system or IT administrator is the primary user of the Cloud Pak for Data System (CPDS) and is responsible for the upkeep, configuration, and reliable operation of the infrastructure so that the tertiary users can use various Cloud services to access and use data needed in their everyday tasks.

Defining Emmet’s goals and pain points
To better understand how a system administrator would engage with CPDS, we interviewed 10 participants working in IT operations roles to uncover their current goals and pain points in maintaining their organization’s infrastructure.

Scoping out the competition

After evaluating multiple competitors in the hyper-converged infrastructure space - especially looking at the leaders in the space - we found that the following trends are what customers look for:

Setting ourselves apart from the competition
“Hills” statements are a fundamental aspect of IBM’s design thinking and they ensure alignment across product teams on an important release goal. They focus on the big problems and outcomes for the users and are meant to communicate the intent for a project with clarity and flexibility, without focusing on a pre-determined implementation. Hills contain three parts: WHO, WHAT, and WOW
Click here to learn more about how we use Hills at IBM as a tool to align teams.
I led multiple virtual and in-person workshops and working sessions with our design team, the offering manager, and the developers to draft, refine, and finalize the Hills statements that best capture the high-level goals of CPDS.
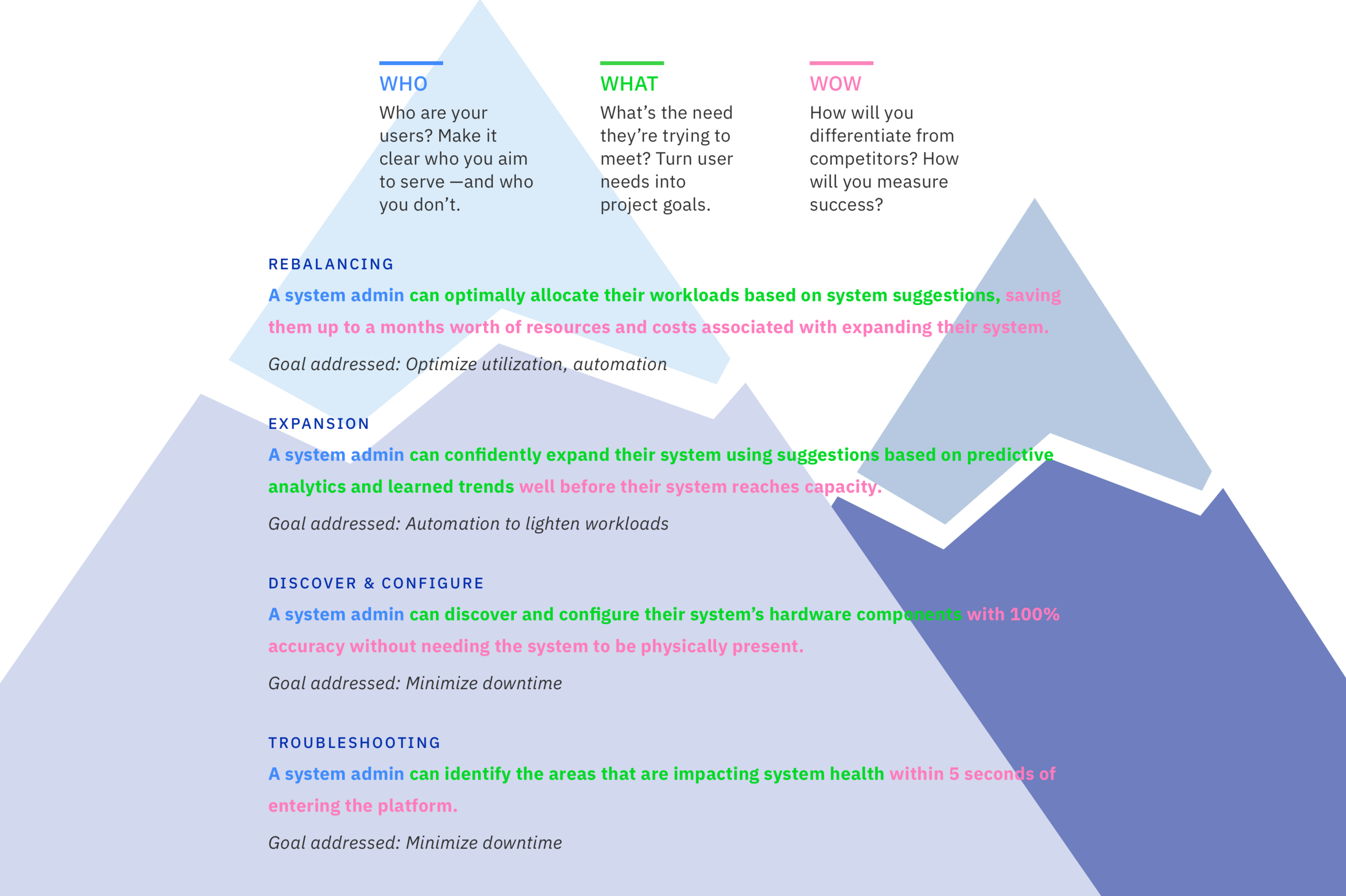
Design, refine, repeat
With these Hills in mind and specific requirements from offering management (OM) and developers, we began ideating on early concepts and user workflows.
In order to ensure alignment between the design, offering management (OM), development, and content teams, the design team held regular, weekly meetings to further discuss requirements, ask questions, get feedback on designs, and give design updates. Additionally, we had 1-2 hour working sessions internally, a few times a week to critique everyone’s work. As a result, we were able to get quick feedback and iterate on our designs each week.

Improving the hardware visualization feature
In addition to internal feedback, we also conducted various usability and concept tests to continuously improve the product for our users. While there were many insights from each of these studies in addition to feedback directly from customers, the part of the product that underwent the most significant changes based on that feedback was the Hardware Overview pages. We found that customers wanted to remotely manage and maintain their hardware components as if they were standing in front of the system themselves and that users would benefit from seeing a graphical visualization of their hardware setup. Thus, we overhauled the initial design and reexamined the overall workflow for how users want to manage their hardware system.


IBM’s Cloud Pak for Data System… today, as we know it
Since January of 2019, when the design team was first introduced to this project and the first GA release a few months later in May, Cloud Pak for Data System has undergone multiple release cycles to get it to what it is now. While this is in no way the “final” design, we have worked relentlessly to put out the best solution for our users and are continuously looking for ways to make the experience better.

Get a quick glance of what’s going on with your system
A high-level look at the make-up and state of your system’s hardware and software as well as the resource usage
Instantly know how many alerts there are and how many are critical (needs immediate attention) vs. minor
Each section has its own drill down page to get more details as needed
Allows users to be more intentional about what or where to focus their attention on first and foremost so that they avoid any possibility of downtime
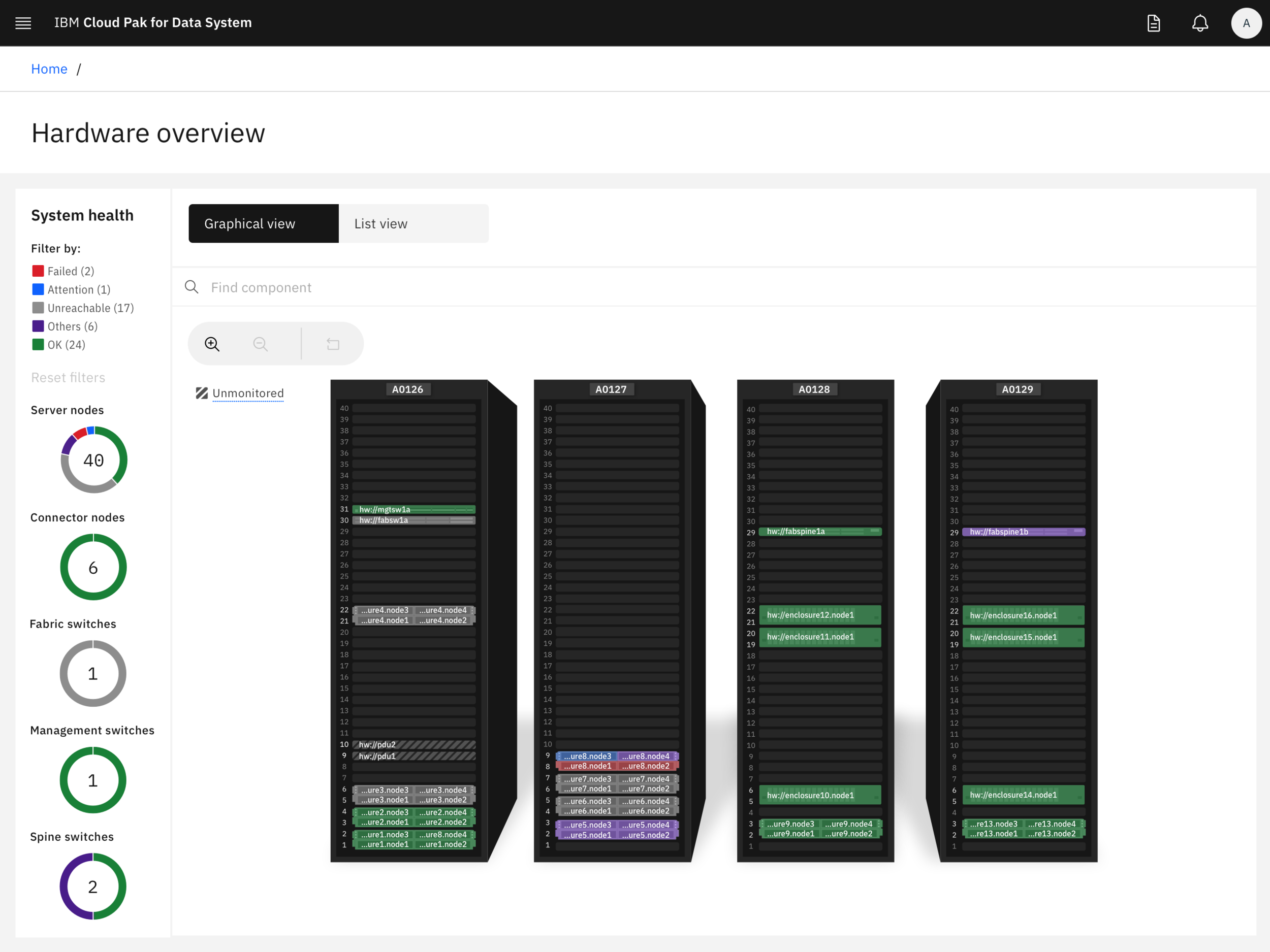

Monitor your hardware as if you’re standing in the data center yourself
Visually manage and organize your hardware racks, nodes, switches, and other components that make up your system
Use the interactive canvas to zoom in to view component details, to filter by status or hardware type, or switch to a list view of the components
Know exactly which components are failing and need attention and where they are located
Users are able to quickly identify and fix problem components or direct the appropriate data center personnel to address the issue(s)

See what software and services are running
Launch runtime instances directly from the platform
View what platform services are running on the system and the status of each service

Understand the breakdown of system resource usage
View interactive data visualizations of various resource metrics (e.g. CPU, storage, network, disc I/O, etc.)
Get a breakdown of how the resources are distributed between software applications and hardware components
Users can use this information to determine whether they need to scale their system up or down to support any and all workloads performed on the platform

Configure newly-installed hardware to your system
Configure the hardware components so that the system can detect and monitor them over time and you can be alerted of any issues that may arise

Organize and prioritize important alerts and notifications
View all your notifications regarding the events and alerts that are happening throughout the system
All notifications are labeled with the severity and details about what component is affected and when it occurred
Open support cases, using the Call Home feature, for issues that require IBM support
Users can stay organized when going through their alerts, ensure that they are addressing the most critical alerts first, and they have at least one path towards a solution to address the problem
So how’s it doing out in the real world?
Highmark Health, based in Pittsburgh, is the second largest non-profit integrated healthcare delivery network in the United States. In 2020, they partnered with IBM to use AI to come up with a solution to their challenges in dealing with the large number of sepsis cases across the country.
Using IBM’s Cloud Pak for Data System to power the services that are included in Cloud Pak for Data, such as Data Virtualization, Watson Studio, Watson Knowledge Catalog, and Watson Machine Learning, they were able to provide a solution that would keep people safe and healthy.
The Problem

Additionally, COVID-19, like other infections, can lead to sepsis and with ICU’s already overwhelmed, this will only strain them further.
Highmark Health gets data from millions of members located across multiple siloed data sources monthly, making it difficult to predict the likelihood of this deadly disease among its millions of members. With the organization’s current architecture, the work done has been cumbersome and clunky, taking months, even up to a year to deploy these predictive models. Even when they made it to deployment, 80% of their AI/ML projects were never even implemented into production.
The Objective
Develop a model and integrate and deploy insights into the existing clinical services application to score and identify high risk patients for sepsis and COVID-19 based on claims data, which will help providers prioritize care, optimize costly inpatient admissions, and hopefully, keep patients at the highest risk out of the hospital.
Their Needs
An integrated platform solution that can handle Highmark’s complex and varied data sets
The capability to deploy models into production to realize the value of the insights into care management applications for proactive outreach
To predict acute events months in advance using claims data from millions of members across multiple siloed data sources
"A platform where we can draw on all of the expertise in our company and build solutions that get ahead of problems, that give us insights into the future that we can act on"
Curren Katz, Highmark Health’s Director of Data Science R&D
The Outcome

With the help of IBM, Highmark Health not only succeeded in their objective of developing a model to identify high risk sepsis and COVID-19 patients, but they did so in a matter of a few short days! By eliminating the multiple data silos, this machine learning model will be able to rank patients by probability of sepsis infection 3 months in advance, which allows their Care Management team plenty of time to take any preventative measures, such as contacting the respective members at risk, checking up on their health, making sure they take their medications, asking questions about potential infections, etc.
Takeaways
Ask questions and for feedback, early and often; be prepared to be wrong
Many of the products at IBM are very technically complex and it is an ongoing process for even the most technically knowledgeable to fully understand the ins and outs. I’ve learned that the phrase “there’s no such thing as a stupid question” is even more relevant at IBM because asking those questions, asking for feedback, and being prepared to be wrong was the only way I could understand the requirements and design an ideal user experience.
Constant and clear communication is essential to ensuring team alignment
Early on in the project, we dealt with some last minute scope creep that forced us to rush certain aspects of the product in order to get it into the release. As a result, we learned to be clearer with our communication by providing a roadmap early and setting stricter cutoff dates but also making sure any updates were communicated to the larger team as soon as possible.